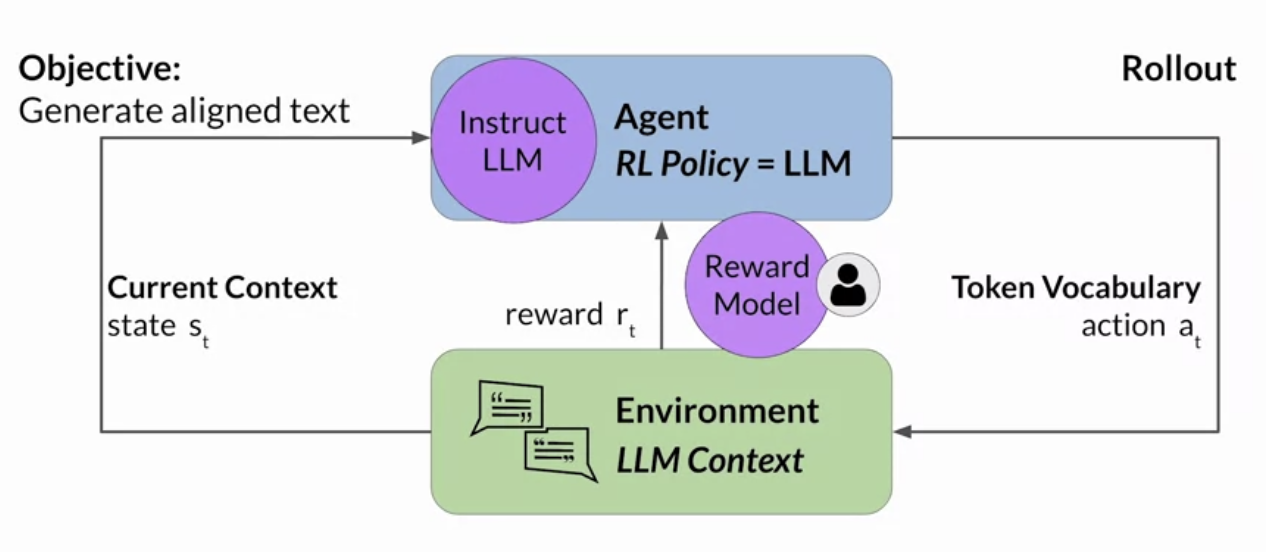
Reinforcement learning with human feedback (RLHF)
What is Reinforcement learning with human feedback (RLHF)
= finetune the LLM with human feedback data, resulting in a model that is better aligned with human preferences.
How it works
-
human labelers score prompt completions, so that this score is used to train the reward model component of the RLHF process:
-
steps
- prepare prompt-response sets to collect human feedback (rankings)
- convert rankings into pairwise training data for the reward model
- train model to predict preferred completion from
for prompt - use the reward model as a binary classifier to provide reward value for each prompt-completion pair
- use a reinforcement learning algorithm (e.g. Proximal Policy Optimization, PPO), to update the weights off the LLM based on the reward is signed to the completions generated by the current version off the LLM
- iterate the cycle until obtaining the desired degree of alignment
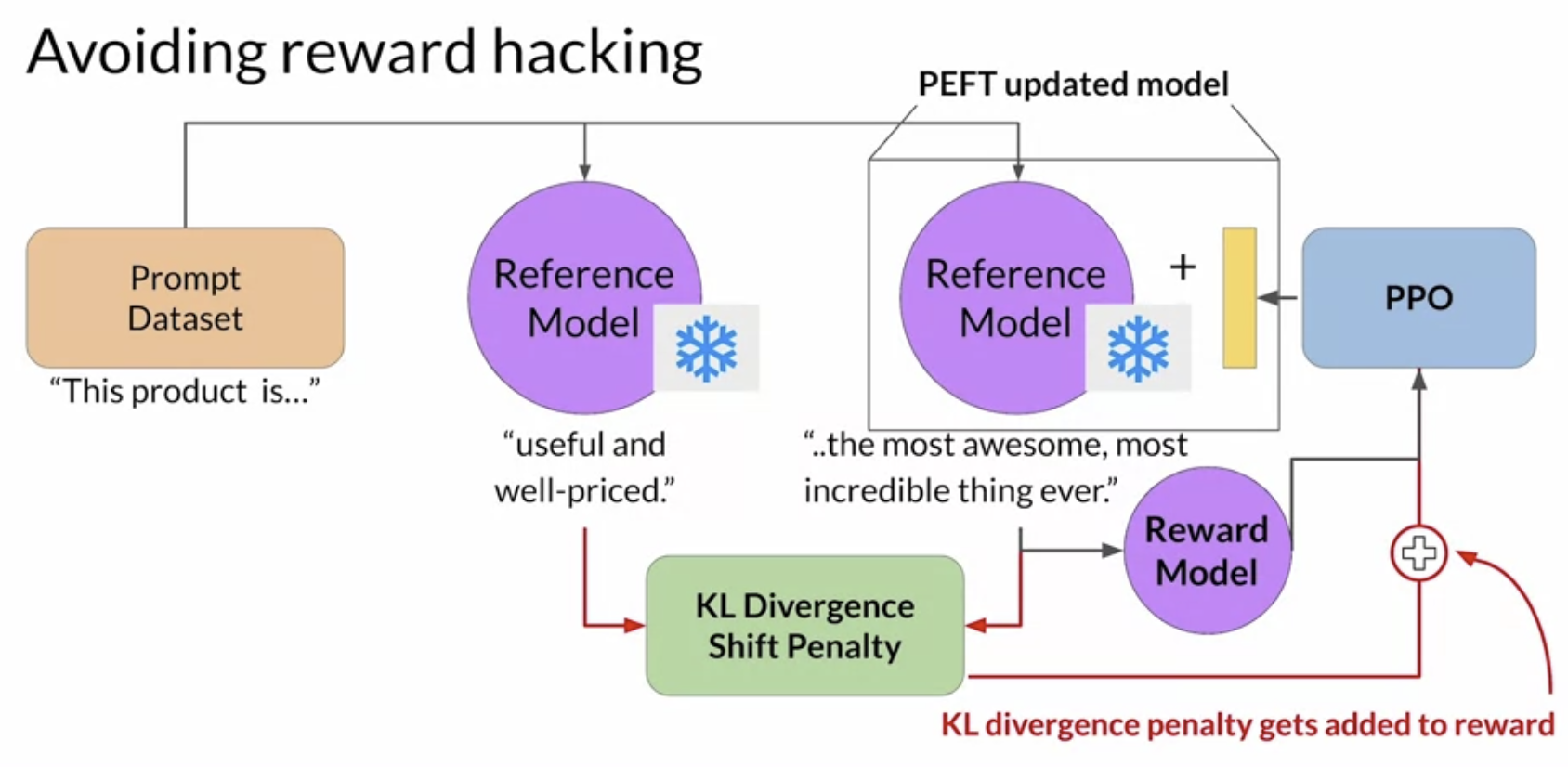
Avoid reward hacking
- What is reward hacking
Reward hacking
- Reward hacking is a problem in reinforcement learning: the agent learns to cheat the system by favoring actions that maximize the reward received even if those actions don't align well with the original objective.
- In the context of LLMs, reward hacking can manifest as the addition of words or phrases to completions that result in high scores for the metric being aligned.
- How to avoid: use the LLM as performance reference